

Un des objectifs majeurs de l’analyse exploratoire des données et probablement le plus important est de proposer un modèle conceptuel génératif de celles-ci. C’est une des différences fondamentales avec la statistique descriptive (voir comparaison statistique descriptive et analyse exploratoire des données) qui se contente de décrire les données à travers une description de la variabilité.
Modèle et modélisation
La fameuse citation attribuée statisticien anglais G.E.P. Box : « Tous les modèles sont faux, mais certains sont utiles » (“All models are wrong but some are useful”) semble relativiser l’intérêt des modèles. Il faut convenir, en effet, qu’aucune donnée réelle, même un simple résultat de pile ou face ne peut être conforme à un quelconque modèle. Cependant, le modèle de Bernoulli représentant le jet d’une pièce est conceptuellement tout à fait satisfaisant et ne sera probablement jamais remis en question.
Un modèle est intéressant en ce qu’il conceptualise la réalité et non pas en ce qu’il la résume. Il représente l’image que l’on se fait de la réalité et non la réalité elle-même. Tous les modèles sont donc peut-être faux dans l’absolu, mais par delà leur utilité, ils peuvent s’avérer tout à fait adaptés à la conceptualisation d’un phénomène et disposer de nombreuses propriétés intéressantes : simplicité, généricité, originalité,… Le modèle de Bernoulli qui représente le jet d’une pièce est, bien que très simple, d’une richesse insoupçonnée, car il génère à lui seul un grand nombre de modèles probabilistes discrets : Binomial, Multinomial, Poissonien, Binomial négatif, et par passage à la limite des modèles continus extrêmement efficaces dont le modèle gaussien.
Un modèle doit donc être jugé à l’aune de ce qu’il apporte de connaissance et de ce point de vue, aucun modèle ne peut être faux, pas plus qu’une carte ne peut être fausse. Tout au plus peut-il être insuffisamment précis ou trop complexe, mais tous les modèles contribuent à la connaissance des processus génératifs des données.
Modèle génératif des données
Il est loisible de proposer une modèle génératif sans s’appuyer sur les données, par exemple en faisant appel à une connaissance extérieure ou antérieure, mais lorsqu’aucune idée a priori n’existe ou, en tout état de cause, que cette idée a priori ne suffit pas à faire une proposition fiable, il convient d’étudier les données avec beaucoup de sérieux pour inférer un modèle conceptuel génératif.
Le modèle conceptuel des données est en fait le modèle probabiliste formel postulé à l’origine des données. Ce modèle est donc, dans les situations mathématiques les plus simples et les plus courantes exprimé à travers la densité de probabilité associée. Il est donc nécessaire, si l’on part des données, d’approcher d’une quelconque manière la densité de probabilité concernée et donc, d’un certain point de vue d’utiliser un estimateur de cette densité de probabilité. La statistique exploratoire est donc, dès lors, manifestement inférentielle en ce qu’elle se réfère au processus d’estimation.
L’histogramme : outil privilégié
L’outil le plus simple, mais aussi de notre point de vue, le plus efficace pour étudier une densité est l’histogramme. Il existe, certes, des outils beaucoup plus sophistiqués qui sont d’un grand intérêt théorique et qui sont aussi très utiles pour étudier des parties spécifiques de la densité comme par exemple, le mode ou les queues de distributions. Mais l’histogramme reste, à notre avis, l’outil le plus susceptible de se prêter à l’analyse et à l’interprétation humaine.
En effet, bien qu’il conduise à une discrétisation (ou quantification), le cerveau humain peut facilement, avec un peu d’habitude, lisser cette discrétisation et appréhender les propriétés générales de la densité sous-jacente : modalité, symétrie,… et envisager ainsi les modèles possibles.
Un exemple d’utilisation
Nous allons travailler sur un exemple particulier pour présenter la démarche de manière intuitive. Les données que nous utilisons sont celles dites des boulons qui sont décrites à boulons.
Intéressons nous dans un premier temps à la variable poids. Cette variable balaie une plage de variation de 7.02 à 7.21 g et bien qu’elle soit naturellement continue, elle apparaît un peu trop discrétisée. L’étude de la densité empirique à l’aide d’un histogramme doit donc être réfléchie. La taille de l’échantillon est 31 et donc le nombre de classes de l’histogramme préconisé par la formule de Dhorne (nombre de classes d’un histogramme) doit varier de 4 à 7 classes. Dans l’optique de nous simplifier la tâche nous allons nous restreindre aux histogrammes à 5 et 6 classes.
Les nombres d’histogrammes de formes différentes à 5 et 6 classes que l’on peut construire sont respectivement de 24 et de 33, comme on peut le voir aux figures suivantes :
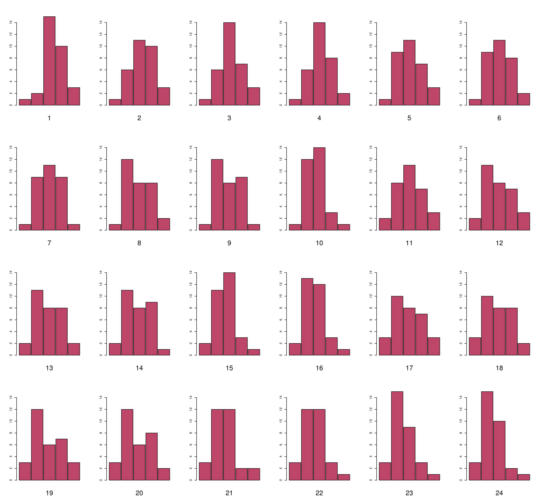
Les différentes formes d’histogrammes à 5 classes du poids des boulons
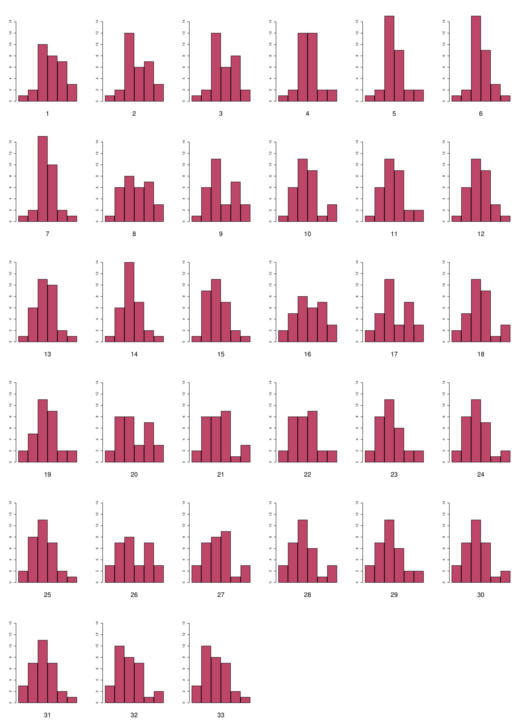
Les différentes formes d’histogrammes à 6 classes du poids des boulons
La qualité de ces histogrammes est très variable, mais 20 sur les 24 à cinq classes et 17 sur les 33 à 6 classes sont unimodaux. Par affectation d’une seule donnée à une classe contiguë, on supprime la multimodalité de tous les histogrammes à 5 classes et il ne reste que 3 histogrammes bimodaux pour les histogrammes à 6 classes. Le caractère unimodal du modèle probabiliste sous-jacent semble donc acquis.
De la même manière, la quasi-totalité des histogrammes laisse apparaître une symétrie ou une pseudo-symétrie visuelle.
Certains histogrammes ont par ailleurs une allure caractéristique de courbe en cloche, comme par exemple les
histogrammes 2 à 7, 11, 13 à 16, 18, 23 et 24 à 5 classes et 4 à 7, 11 à 15, 19, 23 à 25, 29 à 31 et 33. Cette allure de courbe en cloche est caractéristique des modèles dits d’erreurs dont l’exemple le plus emblématique est celui de la gaussienne.
Il est donc, dès lors, compte tenu de la connaissance extérieure que l’on a du phénomène et des conclusions de l’analyse visuelle des histogrammes précédents, tout à fait justifié de proposer comme modèle génératif des poids de boulons un modèle gaussien.
L’étape ultérieure et éventuellement ultime de l’analyse consistera à valider (ou à invalider) ce modèle.